First Order Motion Model for Image Animation
Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci and Nicu Sebe
in NeurIPS 2019

Abstract
Image animation consists of generating a video sequence so that an object in a source image is animated according to the motion of a driving video. Our framework addresses this problem without using any annotation or prior information about the specific object to animate. Once trained on a set of videos depicting objects of the same category (e.g. faces, human bodies), our method can be applied to any object of this class. To achieve this, we decouple appearance and motion information using a self-supervised formulation. To support complex motions, we use a representation consisting of a set of learned keypoints along with their local affine transformations. A generator network models occlusions arising during target motions and combines the appearance extracted from the source image and the motion derived from the driving video. Our framework scores best on diverse benchmarks and on a variety of object categoriesSpotlight video
How does it work?
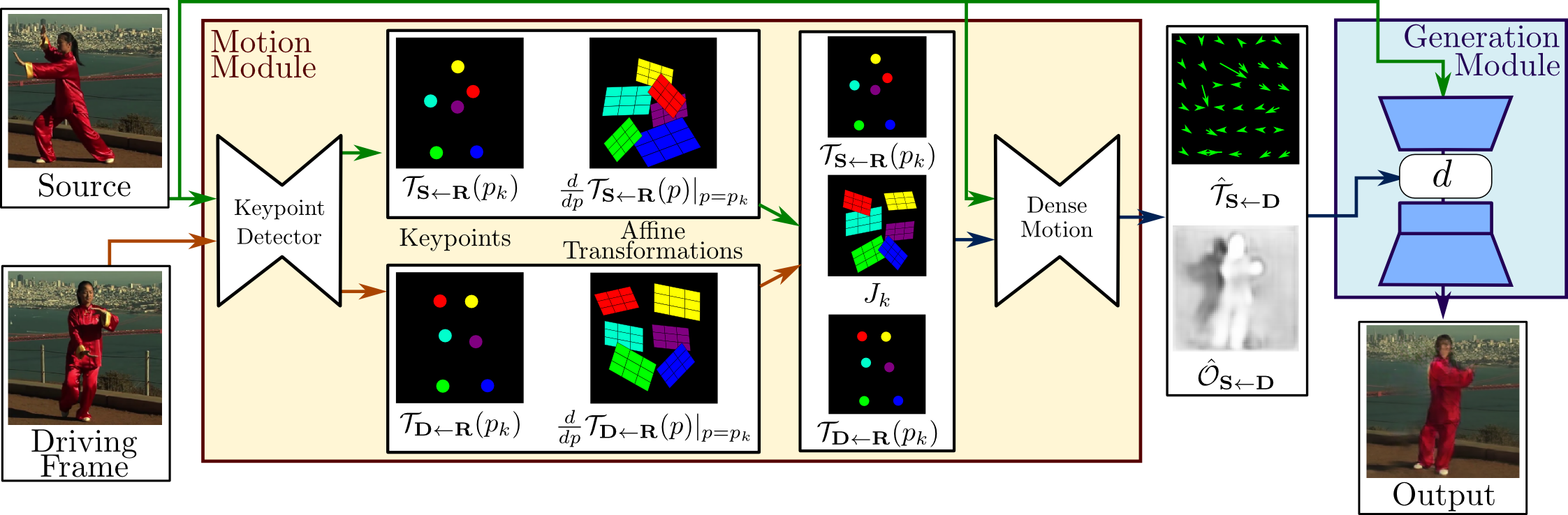
For training, we employ a large collection of video sequences containing objects of the same object category. Our model is trained to reconstruct the training videos by combining a single frame and a learned latent representation of the motion in the video. Observing frame pairs (source and driving), each extracted from the same video, it learns to encode motion as a combination of motion-specific keypoint displacements and local affine transformations. At test time we apply our model to pairs composed of the source image and of each frame of the driving video and perform image animation of the source object.
An overview of our approach is presented in Figure above. Our framework is composed of two main modules: the motion estimation module and the image generation module. The purpose of the motion estimation module is to predict a dense motion field. We assume there exists an abstract reference frame. And we independently estimate two transformations: from reference to source and from reference to driving. This choice allows us to independently process source and driving frames. This is desired since, at test time the model receives pairs of the source image and driving frames sampled from a different video, which can be very different visually.
In the first step, we approximate both transformations from sets of sparse trajectories, obtained by using keypoints learned in a self-supervised way. We model motion in the neighbourhood of each keypoint using local affine transformations. Compared to using keypoint displacements only, the local affine transformations allow us to model a larger family of transformations. During the second step, a dense motion network combines the local approximations to obtain the resulting dense motion field. Furthermore, in addition to the dense motion field, this network outputs an occlusion mask that indicates which image parts of driving can be reconstructed by warping of the source image and which parts should be inpainted (inferred from the context). Finally, the generation module renders an image of the source object moving as provided in the driving video. Here, we use a generator network that warps the source image according to dense motion and inpaints the image parts that are occluded in the source image.
Animation results



Face-swap results

Citation
@InProceedings{Siarohin_2019_NeurIPS,
author={Siarohin, Aliaksandr and Lathuilière, Stéphane and Tulyakov, Sergey and Ricci, Elisa and Sebe, Nicu},
title={First Order Motion Model for Image Animation},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
month = {December},
year = {2019}
}